*Tousse*
Bref.
Donc les gènes. On a vu précédemment de quoi était constitué un génome, ce grand livre de recette d'un organisme : les lettres fondamentales et le papier. Tout ça, c'est bien joli mais cela ne nous dit pas comment la faire cette blanquette de veau. En d'autres termes : comment est codifiée dans un génome l'information servant à la fabrication et la maintenance d'un organisme ?
Tout comme un livre de recette se décompose en plusieurs recettes individuelles, un génome se décompose en plusieurs gènes individuels qui se trouvent à différents endroits du génome.
| Des gènes dans un génome... |
Toujours tout comme le livre de recette (je vais user et user de cette métaphore à vous en faire devenir obèse), une recette va contenir l'information pour un plat en particulier, coder pour un plat pourrait-on dire, un gène va coder pour quelque chose, à savoir une protéine (ça peut être autre chose, mais je ne vais pas en parler aujourd'hui).
| ... qui codent pour des protéines. |
Avant de voir comment cette information est encodée, voyons comment cela fonctionne.
Vous vous souvenez de la cellule et du fait que le génome se trouvait dans le noyau ?
| une cellule |
Et bien les protéines et toute la machinerie qui sert à faire fonctionner une cellule se trouvent dans le cytoplasme. Donc il faut faire transiter l'information génétique du noyau au cytoplasme.
De la même manière, le livre de recette de votre grand-mère, vieux, fragile et précieux, vous n'allez pas le sortir du placard et l'utiliser dans votre cuisine à la merci de toutes les tâches d’œuf, de sauce et d'huile possible. Non, vous allez le laisser dans le placard mais faire des photocopies des recettes qui vous intéressent (différentes selon les envies, les saisons et les invités) et travailler sur ces photocopies.
Ici le principe est rigoureusement identique. Le génome est fragile et important, donc la cellule va photocopier la séquence du gène dont elle a besoin, transférer la copie du noyau au cytoplasme, cette copie va être décodée pour fabriquer une protéine.
La photocopie est faite non pas d'ADN mais d'ARN (Acide RiboNucléique). Vu qu'il existe plusieurs types d'ARN, celui-là on va l'appeler ARNm pour ARN messager.
Schématiquement, ça donne ça pour le livre de recettes.
| Comment cuisiner sans ruiner son livre de recette préféré... |
1) photocopier la recette d’intérêt, 2) transférer la photocopie dans la cuisine, 3) utiliser les infirmations de la recette pour cuisiner le plat et 4) se régaler.
Ça va donner ça pour les gènes :
| Comment produire une protéine... |
1) copier la séquence du gène dans l'ARN messager, 2) transférer cet ARN dans le cytoplasme, 3) utiliser l'information de cet ARN pour fabriquer une protéine et 4), faire fonctionner toute la machine !
Maintenant un petit retour sur cet ARN messager, et plus particulièrement sur l'ARN en lui-même. Il est un peut différent de l'ADN, déjà pour la structure. Vous vous rappelez que la colonne vertébrale d'un brin d'ADN est le sucre (le désoxy-ribose dans ce cas) et bien c'est le même principe pour l'ARN sauf que le sucre est différent, c'est du ribose "normal" (d'où le nom d'ARN). Ensuite les bases sont différentes : les thymines ("T") sont remplacées par des uraciles ("U") (sans rentrer dans des détails qui vont être un peu ennuyeux, la structure chimique est là aussi un poil différente entre une thymine et une uracile). À la séquence d'ADN ATGCATGC correspondra la séquence d'ARN AUGCAUGC. Enfin, alors que l'ADN est double brin (deux brins en sens opposé), l'ARN est simple brin, lui (pourquoi faire compliqué). Sinon tout reste identique, y compris l'orientation du brin dans le sens 5' 3'.
Un autre truc. L'image de la photocopie que je manie à l’excès n'est pas superflue, elle est même fidèle à la réalité. Vous vous souvenez je vous avais dit que dans une hélice d'ADN, un "A" et un "T" se mettaient toujours ensemble, et un "G" et un "C" toujours ensemble. Ce principe marche aussi si vous couplez un brin d'ADN avec un brin d'ARN, avec la petite particularité qu'un "A" de l'ADN se mettra avec non pas un "T" (il n'y en a pas dans l'ARN si vous suivez) mais avec un "U" (alors qu'un "T" de l'ADN se mettra lui avec un "A" de l'ARN sans aucun soucis.
Donc alors comment on va copier la séquence d'un gène dans un ARNm. Ça va fonctionner en plusieurs temps. Je vous avais dit que deux brins d'ADN qui se mettaient ensemble formaient une belle double hélice. On va commencer par dérouler cette hélice mais pas toute l'hélice (sinon ça ferait beaucoup de boulot) mais seulement la région qui nous intéresse (le gène donc). Ensuite on va séparer les deux brins. Comme ça la machine à photocopier aura accès au gène (c'est un peu comme ouvrir le livre de recette à la bonne page et tenir le livre ouvert dans la machine.
En gros, ça donne un truc comme ça :
| Comment photocopier un gène... |
Vous remarquerez que le brin bleu sert de négatif pour copier la séquence du gène qui est sur le brin orange dans l'ARNm. Si on détaille la région du gène, ça va donner ça (avec toujours les deux brins d'ADN en orange et bleu et l'ARNm en rouge) :
| La copie d'un gène dans l'ARNm |
Vous voyez bien comment la séquence du brin principal (en orange) est copié fidèlement dans l'ARNm (en rouge) en se servant de la séquence de l'autre brin comme négatif.
Maintenant qu'on a vu le support physique de l'information génétique, voyons maintenant comment l'information est transmise de l'ARNm à la protéine.
Déjà un petit mot sur la protéine. Tout comme un brin d'ARN ou d'ADN ce sont des bases azotés qui se suivent, une protéine ce sont des acides aminés qui se suivent. Ce sont donc les briques fondamentales de constructions Lego plus complexes. Il y en a 20, de ces acides aminés (certains sont connus comme la lysine dans Jurassic Park il y a 21 ans, je viens de me donner un sacré coup de vieux).
Le principe ensuite est simple : c'est la suite des bases sur l'ARNm dans un gène qui va déterminer la suite des acides aminés. Alors là, si vous avez suivi, vous allez voir qu'il y a un organe reproducteur mâle (une couille, si vous préférez). Il y a 20 acides aminés mais seulement 4 bases. Comment qu'on fait alors ? Et bien c'est simple encore une fois, un acide aminé sera déterminé par non pas une seule (4 bases = 4 possibilités), ni même deux (4 bases * 4 bases = 16 combinaisons possibles) mais 3 bases d'ADN (4 bases * 4 bases * 4 bases = 64 combinaisons possibles).
Du coup, on parlera de triplet ou de codon pour parler des trois bases qui vont coder pour un acide aminé donné.
On peut illustrer ça comme suit. La séquence suivante pourra être vue comme composée de plusieurs codons, chacun identifié par une couleur différente.
La correspondance entre codons et acides aminés se trouve dans un tableau appelé code génétique.
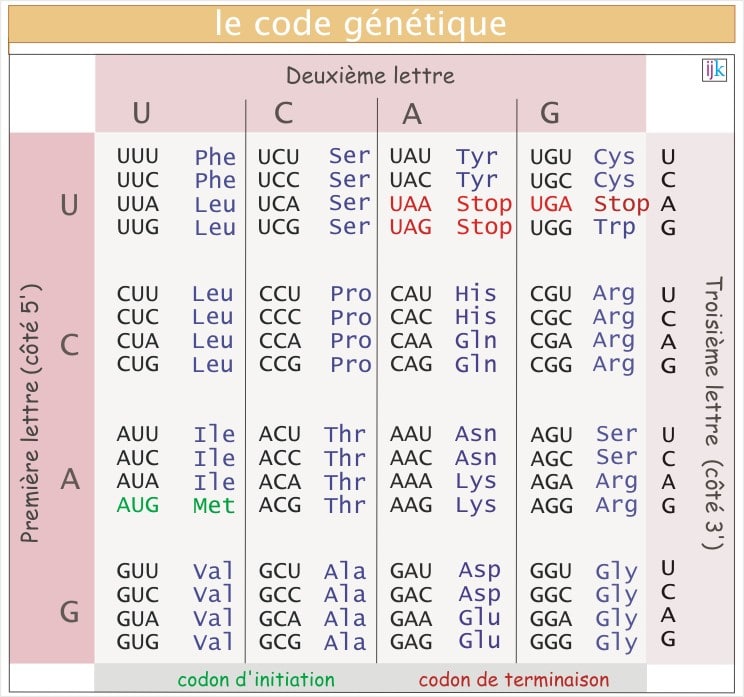 |
| Code génétique |
Alors avant de continuer, un point ultra méga important qui me hérisse le poil. Il y a une
Dans ce tableau, certains codons sont indiqués en vert comme initiation et en rouge comme terminaison. Ce sont en fait les codons qui vont indiquer respectivement le début et la fin du gène (précisément de la partie du gène qui code pour la protéine). Vous remarquerez aussi qu'il y a donc 64 codons possible pour 20 acides aminés. Du coup, certains acides aminés seront codés par plusieurs codons. On parlera alors de redondance du code génétique (avec quelques conséquences sur l'évolution dont je vous toucherai mot plus tard).
Pour simplifier, dans la fin de ce message, on ne parlera que de la séquence d'ADN pour un gène, pas de la séquence de son ARNm.
Bref, si on reprend la petite séquence plus haut et qu'on y applique le code génétique, on aura la protéine suivante :
| de l"ADN à la protéine... |
En vrai, la machinerie cellulaire va lire l'ARNm codon par codon et à chaque codon, va ajouter à la protéine l'acide aminé correspondant.
Pour finir, deux définitions. Quand on copie la séquence d'un gène de l'ADN vers l'ARNm, on appelle ça la transcription, tout simplement car on retranscrit un texte d'un support à un autre, sans changer quoi que ce soit. Par contre, le fait de fabriquer une protéine à partir de l'enchainement des codons s'appelle la traduction, tout simplement parce qu'on va traduire une information, un texte, d'une langue (l'ADN) à une autre (la protéine).
Voilà, c'est fini pour ajourd'hui. La prochaine fois, je vous parlerai de la structure des gènes et de leur régulation (comment on allume ou éteint un gène...)
Bonne fin de semaine.
Aucun commentaire:
Enregistrer un commentaire